Data Source Cleanup
Variable Selection
Due to the constraints of time, bandwidth and knowledge, we opted to choose a limited number of variables from the complete set for the purposes of modeling. The list was reduced to 54 variables, based on research performed by the team that suggested certain elements that might be of most interest to the goal of predicting suicide attempts.
Variable selected for prediction: V6309
V6309 is a Yes/No response question, "Have you ever attempted suicide?"
Value Scraping & Translation
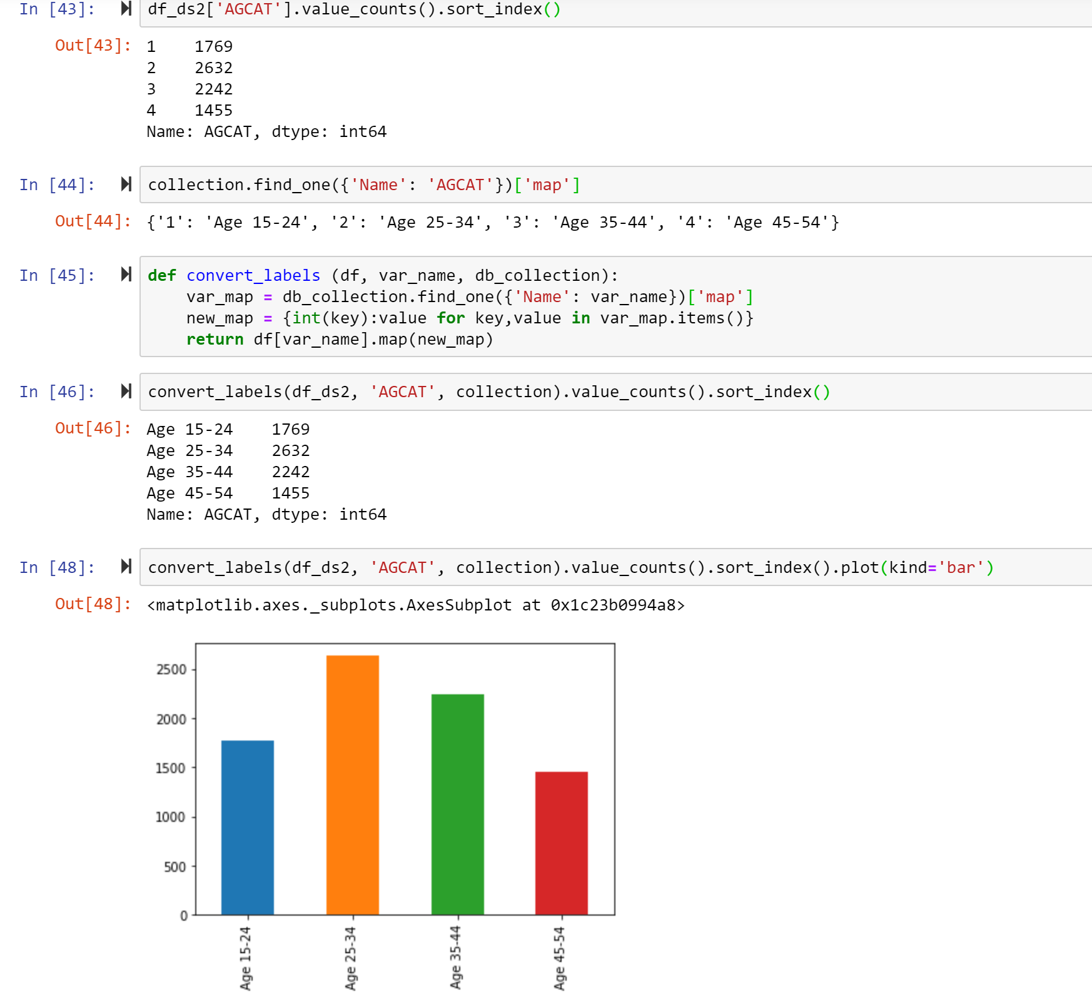
To make use of the integer values and for purposes of readability, we needed to translate them to category lables. This information was available in the study code book, as well as via the ICPSR website.

Using Python, a script was created using BeautifulSoup to scrape all the table values for each variable and convert them into a dictionary format. The dictionary was then used to map the study data values to their respective category labels.
Data Preparation for Model Input
Final steps were performed to prepare the data for entry into the machine learning model:
- Remove missing cases from the response (missing by survey design) leaving 5872 cases.
- Convert categorical predictors to one-hot encoded using pandas.get_dummies(). This increases the number of predictors to 161 – all but one predictor is 0-1-valued.
- Scale the predictors